https://arxiv.org/pdf/2310.15154
LLM이 sentiment관련 task를 풀때 사용하는 direction에 대한 연구
Contribution
1. sentiment의 linear representation을 synthetic data에서 찾음
2. 위 direction으로 실제 dataset에서 correlation, causality를 보임
3. summarization motif라는 emergent behaviour를 확인함
setup
ToyMovieReview :

의 프롬프트로 각 ADJ와 VERB에는 각각 85종, 8종의 긍정적이거나 부정적인 sentiment의 단어를 사용해서 데이터셋을 만들고 긍정적인 경우에서 가장 빈번히 발생한 completion 토큰들, 부정적인 경우에서 가장 빈번히 발생한 completion 토큰들을 각각 예상 completion으로 사용
ToyMoodStory :

의 형태의 프롬프트. 위와 비슷한 방식으로 데이터를 준비한다. 예상 completion은 따로 두지 않고 " excited"와 " nervous"의 logit difference를 모델 출력 평가에 사용
Stanford Sentiment Treebank (SST) :
한 문장짜리 실제 영화 리뷰 데이터. 긍정 부정 annotation이 존재. 위에서는 동일 문장구조에서 토큰들을 변경하는 식으로 positive negative pair를 구축했다면 SST에서는 positive 한 문장들, negative한 문장들 중 그냥 길이(token sequence length)가 같은 문장을 pair로 데이터셋을 구축한다. 이후 patching할때는 "Review Text: TEXT, Review Sentiment:" 형태로 뒤에 "Review Sentiment:"을 append해서 sentiment를 예측하게 함.
Finding Direction
모든 경우 ToyModelReview데이터셋에서만 찾음
1. Mean Difference :

긍정 데이터셋 레이어 L, adjective 포지션의 (residual stream) activation 평균과 부정 데이터셋 동일 위치 activation 평균의 차
2. K-means :
데이터셋 레이어 L, adjective 포지션의 (residual stream) activation을 2개(k=2)의 클러스터링을 해서 centroid의 방향
(c1-c2)
3. Linear Probe :
데이터셋 레이어 L, adjective 포지션의 (residual stream) activation으로 긍정인지 부정인지 logistic regression classifier를 만들었을때 해당 classifier의 normed weight
4. DAS :

theta direction으로 activation patch (DII) 했을때의 logit difference를 train objective로 해서 direction theta를 학습
논문에서 추가적인 설명이 없고 정리된 코드도 없어 틀릴 수 있지만 구현을 이해해 보자면...
위와같이 rotation모듈을 두어 첫번째 column을 patch했을때 prediction이 바뀌도록 (위 logit difference 식)으로 학습하고 rotation matrix의 첫번째 column이 첫번째 column을 만들기 때문에 해당 rotation matrix column을 direction으로 사용
위와 다음은 수학적으로 동치임
5. PCA :
데이터셋 레이어 L, adjective 포지션의 (residual stream) activation 총 datapoint개를 PCA한 direction
위와같이 direction을 찾았을때 각 direction vector의 cos 유사도를 측정한 결과 각 direction이 매우 유사하다. (gpt2-small 결과)

즉 각 방법이 실제 유일한 sentiment direction의 approximation이라고 생각할 수 있다. 놀랍게도 K-means와 같은 unsupervised 방식도 유사한 direction을 찾아냈다.
Direction Correlational Evaluation and Results
GPT4에게 OpenWebText context를 주고 각 토큰에 대해 positive, neutral, negative중으로 classify하게 하고 그 결과를 gpt2-small 첫번째 레이어 residual stream의 sentiment direction activation에 plot해보면

위와같이 activation에 따라 positive와 negative가 구분되고 사이에 neutral이 존재함을 볼 수 있다.

위는 각 방법에 따른 accuracy (top/bottom 0.1%의 activation이 각각 postive인지 negative인지)

gpt2-small 각 레이어 residual stream의 각 방법으로 찾은 direction의 activation. 빨간색이 negative activation, 파란색이 positive activation. 레이어 초기에는 각 토큰을 따라 negative하게 activate했다면 후반부 레이어에서는 negation을 반영해 positive하게 뒤집힌다.
Direction Causal Evaluation and Results
directional patch
위에서 설명한 DAS와 동일한 방식으로 pair를 만들어 놓은 데이터셋에 대해 각 방법으로 찾은 direction에 activation patch한다.
각 방법으로 찾은 direction을 directional patch했을때

위와같이 pair를 정확히 맞춰놓은 ToyMovieReview에서는 100% 모든 데이터의 sentiment 예측을 flip할 수 있었고 형태를 맞추지 않고 길이만 동일한 데이터로 pair를 맞춘 데이터에서는 50%가량의 데이터를 flip할수 있었다. 특히 unsupervised하게 찾은 direction으로도 어느정도 flip이 가능했다.
direction을 찾을때는 ToyMovieReview의 adjective부분만을 이용했기 때문에 unseen distribution에도 잘 적용된다고 볼 수 있다.

directional patch 레이어에 따른 logit difference. 초반 레이어나 후반 레이어가 아니라 중반 레이어에 patching하는게 가장 effective하다. 즉 token단위 의미의 sentiment를 사용하는게 아니라 모델이 실제로 사용하는 feature를 찾았다고 볼 수 있다.
activation addition

긍정적인 movie review prompt에서 sentiment direction에 낮은 coefficient로 activation addition했을때의 생성을 GPT-4가 평가했을때 negative한 생성을 하게되는것을 확인할 수 있다.
어느 레이어 어느 포지션에 하는지 설명이 없고 코드에서도 찾을수 없었다. 특정 레이어 특정 포지션에 하고 최고로 좋은(많이 flip된) 경우를 report한듯 함
Circuit analysis
path patching
(https://arxiv.org/abs/2211.00593)
activation patching 의 한 종류를 사용해 가장 logit 차에 영향을 크게 주는 모델 component를 찾는다.
모델 내부의 computational path를 그래프로 나타내서 설명하면 (각 노드가 mlp, head같은 모델 component)
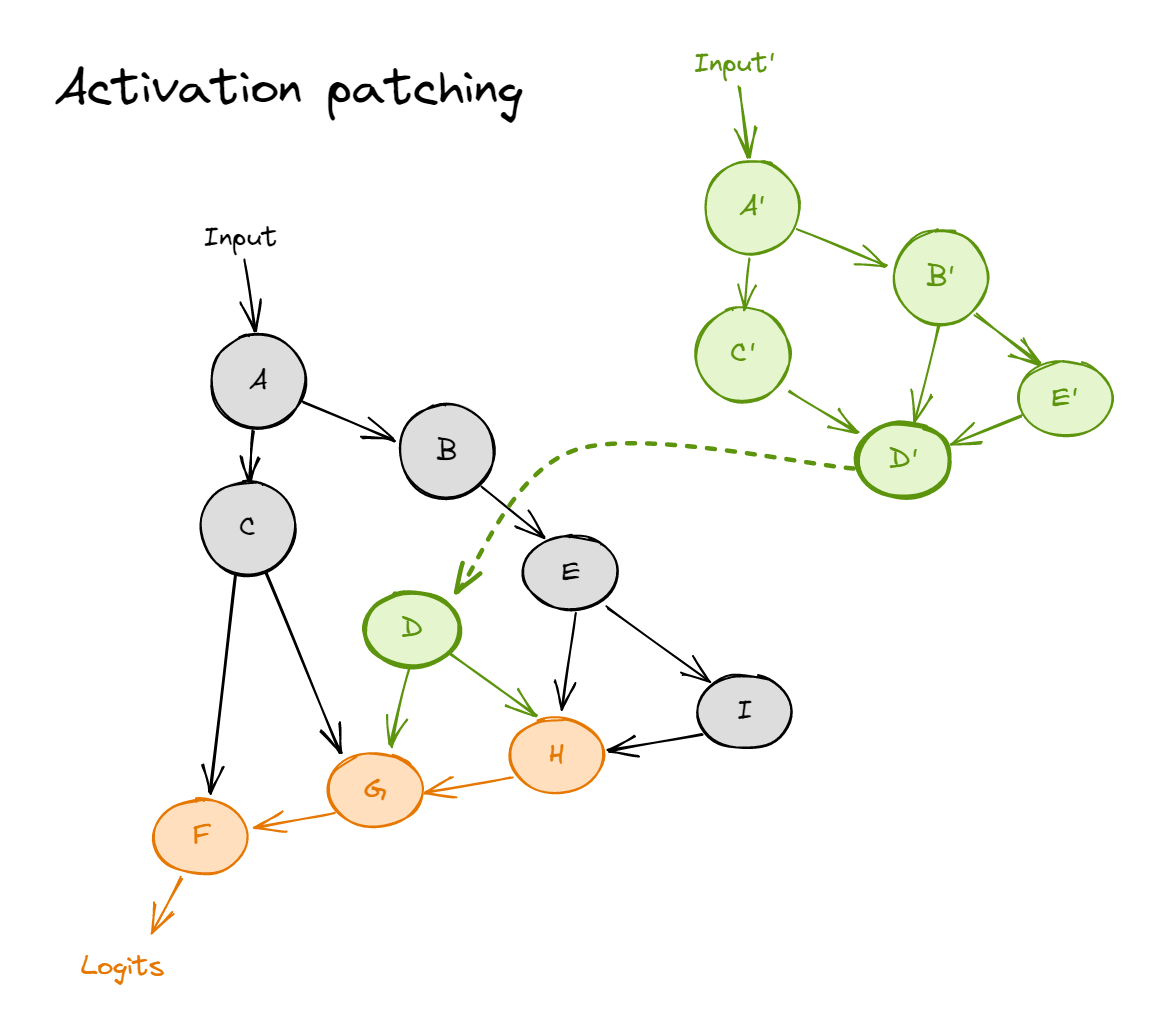
위가 activation patching. 원래의 forward pass가 아래 회색으로 표시된 부분. 녹색의 activation을 주입하면 그 이후 그에 dependent한 computation이 영향을 받는다(위 그림에서는 붉게 표시한 부분).
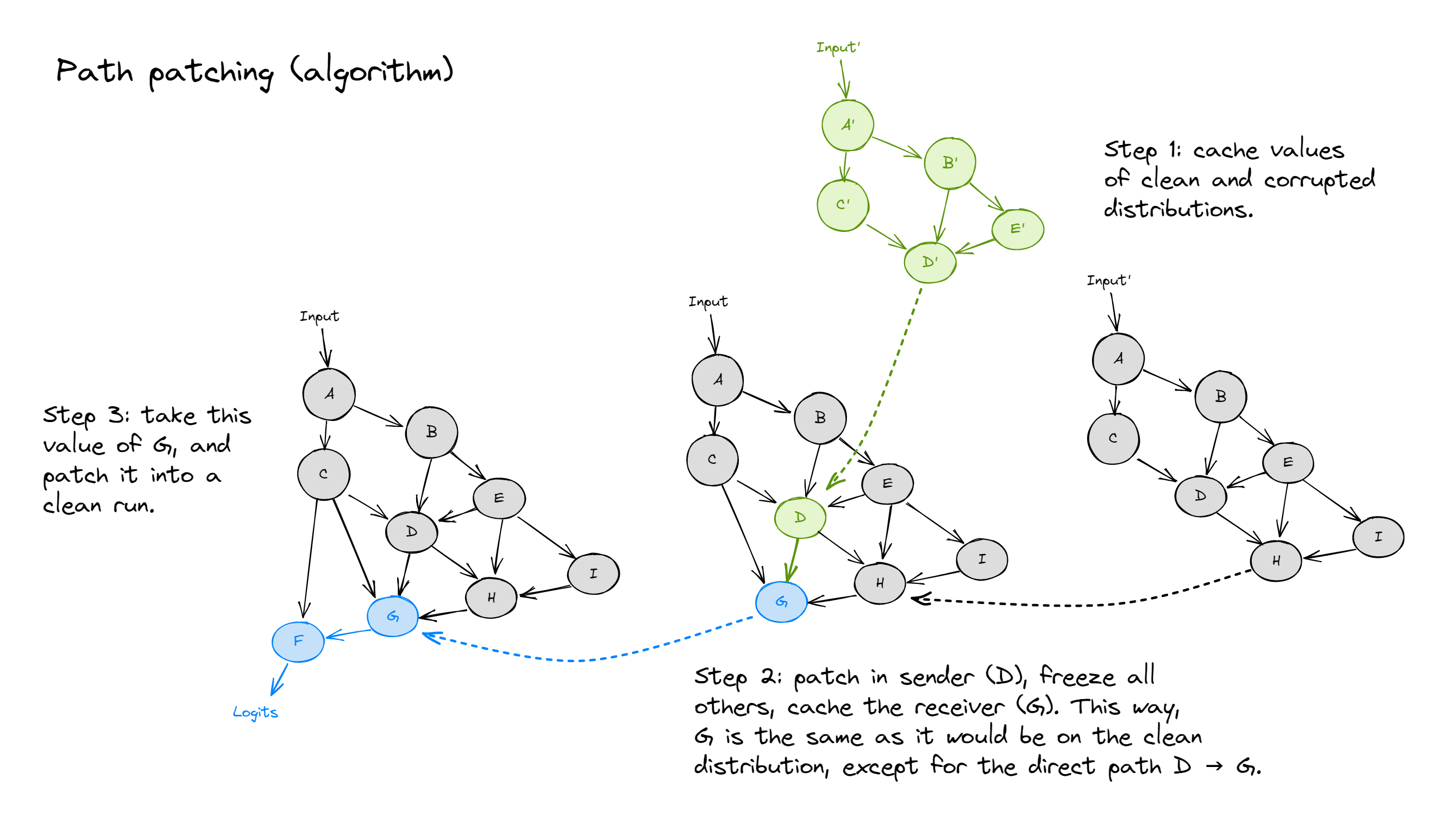
path patching은 위 그림에서는 D에 해당하는 모델 component가 G를 통해 logit에 미치는 영향만을 patching한다. 이때 D를 sender, G를 reciever라고 하는데, path patching은 sender가 reciever에 직접적으로 미치는 영향만을 patching한다.
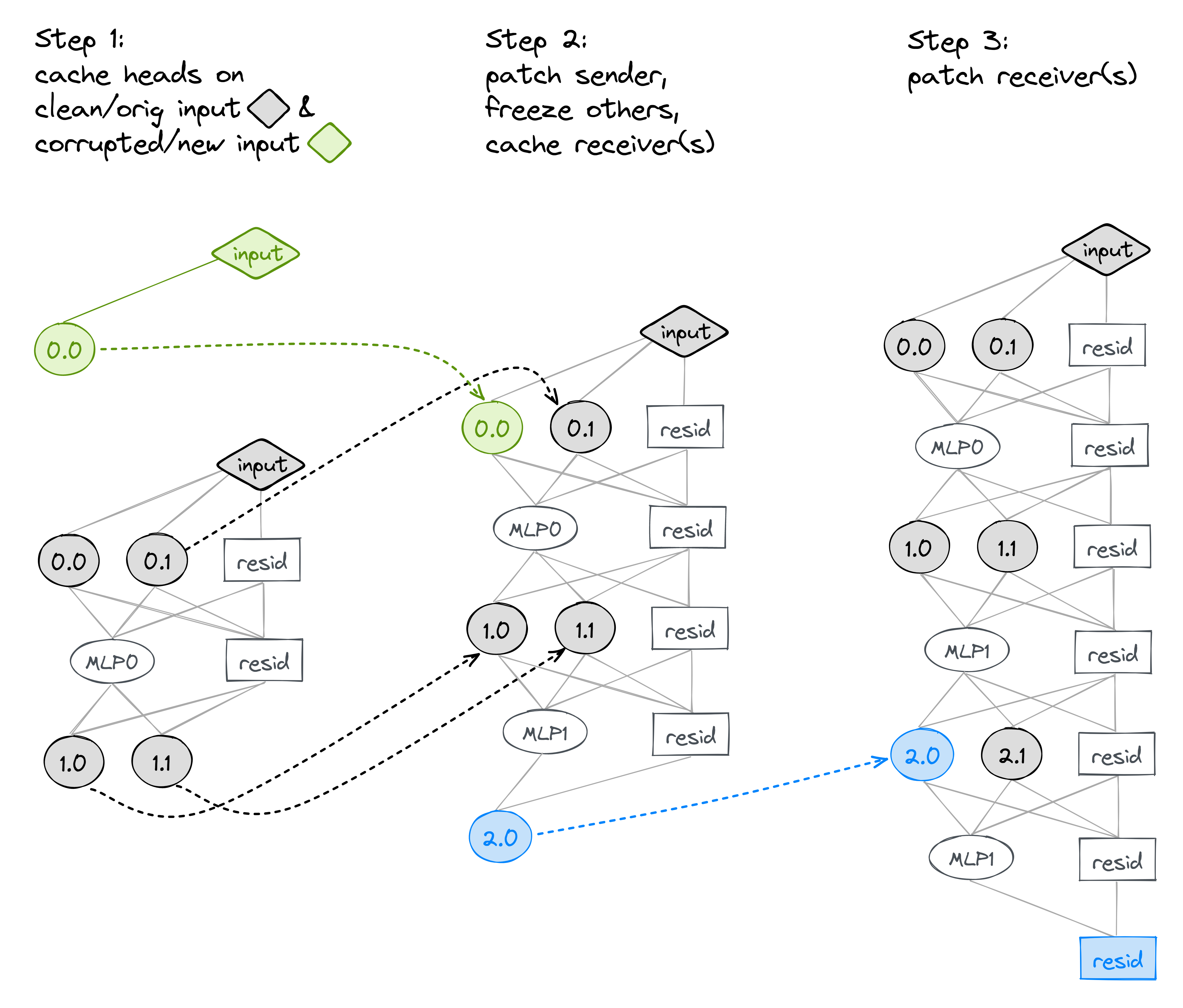
레이어 3개 어텐션 2개짜리 트랜스포머에서 sender를 첫번째 레이어 첫번째 어텐션헤드 0.0으로 하고 reciever를 세번째 레이어 세번째 어텐션헤드 2.0이라고 하면 위 그림과 같다. 회색은 patch당할 forward pass의 activation을 강제로 주입한 부분. 녹색은 patch할 activation을 주입한 부분. 흰색은 그냥 모델이 각각 patch했을때 자연스럽게 생성한 부분.
이 논문에서는 reciever를 마지막 residual stream으로 하고 sender를 바꿔가면 실험. logit difference에 가장 크게 영향을 준 component를 찾는다.
찾은 component (attention head만 확인한 듯 함) 의 attention pattern을 분석, 다음과 같은 circuit을 찾아낸다.

sentiment task를 풀기 위해
1. 직접적으로 positive/negative한 token을 보고 contribute하는 에텐션헤드 (10.1 10.4 11.9) (각각 레이어 10 1번헤드, 레이어 10 4번헤드, 레이어 11 9번헤드 라는 뜻)
2. summary token 을 보고 contribute하는 어텐션헤드 (8.5 9.10)
3. summary token position에 positive/negative한 token을 보고 정보를 쓰는 어텐션헤드 (7.1 7.5) (path patching 으로 발견)
4. positive/negative한 token, summarization token 모두 보는 헤드 (9.2)
를 이용한다.

위 4가지 분류에 속하는 헤드중 가장 역할이 큰 9개를 circuit으로 했을때
1. circuit전체를 ADJ, VRB ( positive/negative한 token )위치에서 반대 문장의 activation을 patch했을때 97%의 logit flip, 75%의 logit difference를 achieve
2. 위와 같이 circuit전체 동일 위치에서 sentiment direction의 성분만 patch했을때 58%의 logit flip, 54.8%의 logit difference.
sentiment directio이 이 circuit에서도 주요한 역할을 함을 알 수 있다.
Circuit on Pythia2.8b
위의 ToyMoodStory 데이터셋을 풀 수 있는 가장 작은 모델 pythia에서 gpt-small과 마찬가지 방법으로 circuit을 찾는다.
과정은 위와 동일하여 생략, 주요 결과만 정리하면
1. 주로 "," 토큰을 보는 어텐션헤드가 존재 (VERB1 parties 다음의 ",").
2. 위 헤드에 path patching한 결과 ","포지션이 가장 민감함
3. 위 헤드는 주로 QUERYNAME, feels 포지션에 정보를 쓰고
4. 후반 레이어 특정 헤드는 위 QUERYNAME, feels포지션을 읽고 sentiment를 예측함
"," 토큰에 저장된 정보를 파악하기 위해 activation patch를 한다.
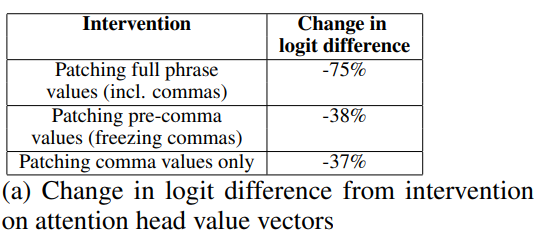
comma에서 같은 정보를 가져오도록 attention patterm을 freeze하고 VERB1 parties 포지션에 patching
(patch하는 component나 레이어는 논문에 없고 코드는 찾지못함. 아마 특정레이어 residual stream)
comma 포함 프롬프트 전체를 flip된 프롬프트로 patch한 경우 logit difference가 -75%
comma 포지션 activation은 freeze하고 그 전 포지션만 patch한 경우 logit difference가 -38%
comma 포지션만 patch한 경우 logit difference가 -37%
즉 ","포지션이 실제 VERB1처럼 sentiment를 나타내는 토큰과 유사한 정도의 영향을 미친다
","에 저장하는 summarization은 sentiment task에 irrelevent한 text가 추가되어 context가 길어졌을때 더 큰 영향을 미친다.
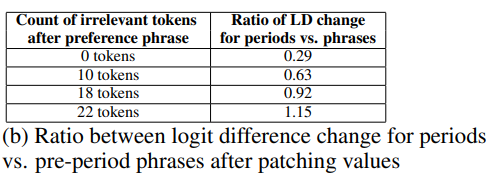
22토큰 길이의 irrelevent context가 주어진 경우 실제 positive/negative한 토큰보다 15%더 큰 영향을 준다.
In non-toy texts (SST)
위에서 설명한 Stanford Sentiment Treebank데이터셋, pythia-2.b을 사용해 sentiment classificaion에 성공한 데이터 중 ","가 포함된 데이터를 사용한다. (즉 base accuracy가 1)
1. directional ablation
모든 레이어 모든 포지션 residual stream에 DAS로 찾은 sentiment direction을 ablate (mean ablation)했을때 logit difference -71%, accuracy -38%(즉 68%)
동일 방식으로 무작위 direction으로 ablate했을때 logit difference, accuraacy 감소량은 1% 미만
2. comma position에서만 directional ablation
위 directional ablation과 동일하게 하되 ","포지션에만 하는 경우 logit difference -18%, accuracy -18%.
즉 sentiment direction을 이용해서 task를 푸는 능력의 절반 가량은 "," 포지션을 통한다.
3. ablate on comma position
"," 포지션의 (direction에 상관없이) activation을 데이터셋 전체에서 ","의 acitivation의 평균으로 대체, logit difference -17%, accuracy -19%.
Discussion
1. 모델이 내부적으로 사용하는 direction을 아주 디테일하게 causal, correlational 모두의 근거를 들어 잘 보여줌
2. direction을 여러 방법으로 찾아내고 그 유사성을 보이고 interpretability illusion을 줄임
3. summarization motif; 토큰단위로 주요한 포지션 이후에 정보를 저장하는 mechanism에 대해 잘 밝혀냄