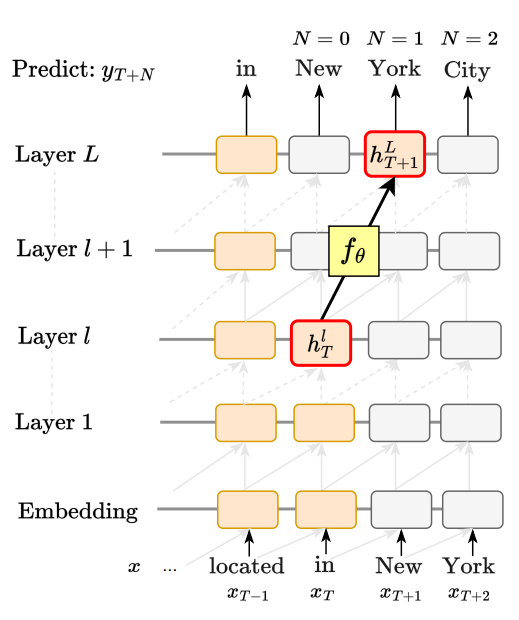
https://arxiv.org/pdf/2406.13663RAG document에서 찾은 문서에서 정답 생성시 attribution (citation)을 생성Related worksanswer attributionRAG에서 retrieved document중 어느것이 생성된 answer를 support하는지 찾아낸는것https://aclanthology.org/2023.emnlp-main.398.pdf에서는 hard prompt + ICL(few shot example)로 LLM이 citation을 작성하게 하고response를 sampling할때 여러개(4개)를 뽑아서 위와같이 NLI를 사용해 citation을 평가, citation recall이 가장 좋은 response를 선택하여 사용 https:..