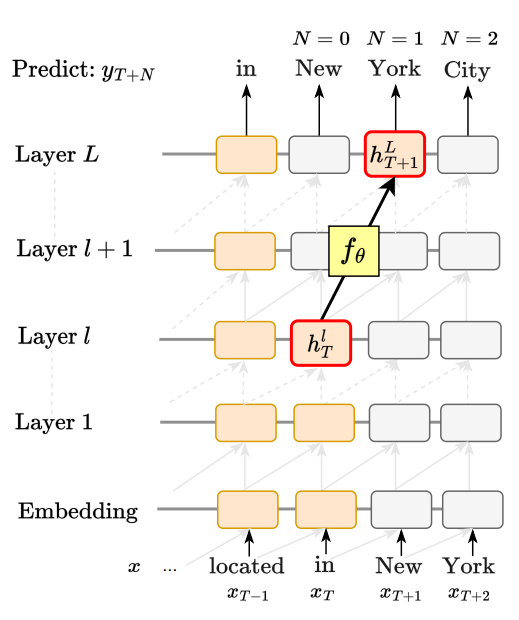
iclr 2025 submission중 재밌어보이는거 모음 (reading list)넘기면서 읽은 내용 정리 https://openreview.net/pdf?id=SfNmgDqeEaLOOKING BEYOND THE TOP-1: TRANSFORMERS DETERMINE TOP TOKENS IN ORDERGPT계열에서 아래단 레이어에서 (logit lens상)어떤 토큰을 예측할지 결정했을때 그 이후 레이어에서 뭘 하는지에 대한 연구. 추가적으로 early exiting 성능향상 https://openreview.net/pdf?id=z1mLNhWFyYGRADIENT ROUTING: MASKING GRADIENTS TO LOCALIZE COMPUTATION IN NEURAL NETWORKS모델을 학습시킬때 특정..