https://arxiv.org/pdf/2406.12775
LLM이 multi-hop QA (closed book, zero shot)을 어떻게 하는가? 틀리는 경우 왜 틀리는가?
multi-hop query : 단계적 추론이 필요한 문제들; 예를 들어 "The spouse of the performer of Imagine is" 다음 토큰을 예측하려면
1. Performer of Imagine is : John Lennon
2. Spouse of John Lennon is : Yoko Ono
를 단계적으로 풀어야 한다. 물론 위 정보를 한번에 저장하고 읽을 수 있지만 그렇지 않음에 대해서도 다룬다.
논문에서는 정확히는 2-hop query에 대해서만 다룬다.
Setup
Dataset
KG 형식의 데이터셋 Wikidata에서 특정 entity를 tail로 갖는 triple과 head로 갖는 triple, 총 2개를 sample하여 template을 통해서 하나의 쿼리로 만든다.

이렇게 만든 쿼리 중 e1 이 없는 경우 혹은 r1이 없는 경우에도 모델이 맞추는 경우 multi hop reasoning을 하지 않는다고 간주, 데이터셋에서 제거한다.
예를들어 위 The spouse of the performer of Imagine is 에서
e1이 없는
"The spouse of the performer is" 를 맞춘다면 general 하게 popular한 entity로 e3를 predict한다고 간주, 배제하고
r1이 없는
"The spouse of Imagine is" 를 맞춘다면 단순히 e1(Imagine)과 e3(Yoko Ono)의 연관성으로 맞춘다고 간주, 배제한다.

총 82000개 가량의 데이터에서 70000개 가량 남고 그중에서 sampling해서 사용한다.
2 hop query는 1 hop query 2개 로 나누어 볼 수 있다. 예시문장에서 "The spouse of the performer of Imagine is" 를 "The performer of Imagine is" 와 "The spouse of John Lennon is" 로 나눌 수 있다.
위 표에서...
correct의 경우 모델이 2 hop query에서 1 hop query 2개를 따로따로 맞추고 2 hop query도 맞추는 경우
incorrect의 경우 모델이 2 hop query에서 1 hop query 2개를 따로따로는 맞추지만 2 hop query는 틀리는 경우
Model
위 표에서와 같이 다양한 버전, 크기의 LLaMA모델을 사용한다.
7,8B 모델은 총 32layer
13B 모델은 총 40layer
70B 모델은 총 80layer
First Hop
모델이 실제로 단계적으로 prediction을 만들어간다면 우선 first hop, 예시에서는 "performer of Imagine is John Lennon" 을 알아내는 과정이 있을것이고 이걸 찾겠다.
찾는 쿼리에서의 포지션 : The spouse of the performer of Imagine is 밑줄친 " Imagine" 토큰 포지션 (" is"자리의 토큰을 예측할때)
찾는 모델에서의 위치 : 레이어 단위, residual stream에서
찾는 방법 : Patchscope
찾는것 : John Lennon
Patchscope

현재 예시에서 좌측 source가 "The spouse of the performer of Imagine is" 가 되고 " Imagine"(e1)을 처리할때의 residual stream을 우측 target prompt에 patch 하여 "John Lennon"(e2)이 디코딩 되는지 확인한다.
우측 prompt로는
"Syria: Syria is a country in the Middle East, Leonardo DiCaprio: Leonardo DiCaprio is an American actor, Samsung: Samsung is a South Korean multinational corporation, x"
를 사용하고 " x"의 인풋을 처리할때 중간 layer에 " Imagine"(e1)을 처리할때의 residual을 patching한다.
만약 residual stream이 "John Lennon"을 담고 있다면 x이후 디코딩에서 " : John Lennon is ~~ " 이런 식으로 생성할 것이라는 method
Experiment results

1. 모델이 실제로 two hop query 을 맞추는가에 상관없이 t1(Imagine, e1 포지션)에서 유의미한 비율로 e2를 디코딩할 수 있다.
2. 모델이 two hop query 을 틀리는 경우 전반적으로 디코딩이 조금 덜 된다.
3. 모델이 two hop query 을 틀리는 경우 전반적으로 더 뒤 레이어(source)에서 디코딩 된다.

LLaMA 2 13b 에서 디코딩이 성공한 경우 어디에서 성공했는지를 비율로 표시한 heatmap
앞쪽 source layer에서 디코딩이 주로 되고 뒤쪽 레이어에서 logit lens 스타일로 일부 디코딩되는것을 확인 할 수 있다.
Information Propagation to Last Token
appendix라서 내용이 적다
t1 (Imagine, e1 포지션)을 처리할때 first hop을 풀었으니 이를 second hop을 풀어야 하는 last token 포지션 (t2)로 옮겨야 한다.
찾는 쿼리에서의 포지션 : The spouse of the performer of Imagine is 밑줄친 " is" 토큰 포지션 (" is" 다음 토큰을 예측할때)
찾는 모델에서의 위치 : 레이어 단위, residual stream / attention
찾는 방법 : Patchscope / attention knockout + sublayer projection
찾는것 : "John Lennon" (e2)
Attention Knockout
7개 레이어씩 window로 해서 해당 레이어들 어텐션 스코어에서 " is" (t2) 다음 토큰을 예측할때 " Imagine" (t1)을 보지 못하도록 masking (activation을 -infinite로) 한다.
Sublayer Projection
각 레이어 MLP, 어텐션의 contribution을 unembedding해서 " John Lennon" (e2)에 대한 정보가 있는지 확인한다
Patchscope
위와 마찬가지 방법으로 t2포지션에서 e2가 존재하는지 확인한다.
Results
위 세가지 방법중 하나로라도 e2를 찾을 수 있는지, 찾는다면 평균적으로 어느 레이어에서 처음으로 찾아지는지 보고한다

아래는 Patchscope의 결과


first hop을 처리한 뒤의 레이어들에서 t2에서 e2정보를 받았음을 확인할 수 있다.
Second Hop
t1(" Imagine")에서 e2("John Lennon")의 정보를 t2(" is") 에서의 residual stream으로 옮겼으니 이제 second hop ("Spouse of John Lennon is") 를 풀어야 한다.
찾는 쿼리에서의 포지션 : The spouse of the performer of Imagine is 밑줄친 " is" 토큰 포지션 (t2) (" is" 다음 토큰을 예측할때)
찾는 모델에서의 위치 : 레이어 단위, residual stream / attention / mlp
찾는 방법 : Patchscope / sublayer projection
찾는것 : "Yoko Ono" (e3)
Results
Patchscpoe

평균적으로 t1(" Imagine") 포지션에서 e2를 디코딩 성공한 레이어보다 뒤 레이어에서 디코딩됨.
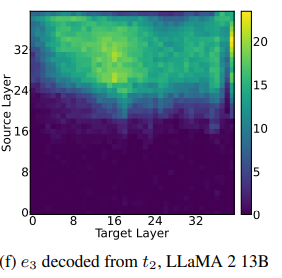

Sublayer Projection

평균적으로 MLP가 Attention 보다 더 큰 역할을 수행함을 알 수 있음
Comparing Correct and Incorrect
모델이 two-hop query를 어떻게 푸는지 살펴봤으니 틀리는 경우와 맞추는 경우를 비교해서 왜 틀리는지를 알아보겠다.

모델이 two-hop query를 틀린경우, 맞춘 경우와 비교해서
1. first hop resolve (t1에서 e2 를 찾은 레이어) 위치가 더 늦다
2. 그런데 info propagation과 prediction extracted (logit lens상 모델이 답을 이미 결정한 레이어) 위치는 이르다
여기서 모델이 first hop을 풀기 전에 second hop을 풀 수 있는 레이어로 정보를 전달하려다 보니 실패가 나타난다고 해석할 수 있다.
Backpatching
모델이 first hop을 푼 정보를 second hop을 풀때 이용하지 못해서 혹은 first hop을 푼 후에는 더이상 second hop을 풀 수 없는 레이어만 남아있어서 실패가 발생한다면...

first hop을 푼 모델상태를 second hop을 풀기 전에 강제로 다시 주입하면 풀 수 있다.
t2(" is")에서 다음 토큰을 예측할때 source 레이어에서
t1(" Imagine" 포지션)에서의 d_model 크기 벡터
t2(" is" 포지션)에서의 d_model 크기 벡터
를 source보다 앞의 target 레이어 해당 위치에 주입했을때

맞추던걸 틀리게 되지 않으면서 틀리던것 중 36-57%를 맞추게 된다.

t1, t2포지션별 patching 했을때 정답을 맞추게 되는 source, target layer 비율
t1 포지션의 경우
1. 초중반쯤의 source레이어를 뽑는게 성공률이 높음. 이는 first hop을 푼것으로 위에서 찾은 레이어와 유사함
2. taget 레이어가 후반부에 있다면 성공률이 0에 가까움. 위에서 찾은 fail mode와 동일한 이유로 fail하게 되기 때문
t2 포지션의 경우
1. t1과 다르게 souce레이어를 후반부 레이어로 뽑는게 성공률이 높음. second hop query를 resolve 한 뒤의 레이어를 patching해야하기 때문
2. target레이어가 초반에 있는게 성공률이 높음. second hop을 풀때 early layer의 정보를 사용할 수 있고 더 많은 layer상의 "시간"을 이용할 수 있기 때문.
Discussion
1. LLM이 단계적 추론이 필요한 수학을 못하는 이유에 대한 설명이 될지도?
2. COT가 잘 되는 이론적인 이유가 될지도? => 모델이 자체적으로 backpatching하는것과 사실상 동일해보임
3. Patchscope, Attn knockout 등을 잘 이용한 case
4. t1(performer of Imagine)을 처리할때 e2, e3를 모두 갖고 있을 수도 있는데 이에대한 확인 無
5. tuned probe를 사용하는 method보다 많이 approximated된 결과같아보임
6. transformer 모델의 구조적 한계에 대해 굉장히 잘 보여줌 => 모델의 크기와 상관없이 단계적 추론을 하려면 순서가 맞아떨어져야 하고 그 정보를 처리할 position적 공간이 필요함