https://arxiv.org/pdf/2401.01967
Introduction

Related works
1. Transformer MLP unembeded : 이 논문 과 이 블로그포스트에서 트랜스포머 각 mlp output 뉴런의 weight을 unembed layer에 통과시켜 나온 logit으로 interprete함
2. https://arxiv.org/pdf/2311.12786 등에서 finetuning의 영향을 mechanistic 하게 interprete함
Contribution
1. 위 mlp unembedding을 이용하여 gpt2-medium에서 toxic한 contribution을 하는 neuron을 찾은 뒤
2. 이를통해 toxic generation을 suppress하고
3. DPO를 통해 toxicity를 줄인 모델이 어떻게 toxicity를 줄였는지 위 뉴런/벡터를 통해 해석하고
4. 이 해석을 바탕으로 DPO를 unalign(jailbreak) 할 수 있음을 보임
Preliminary
https://arxiv.org/pdf/2012.14913
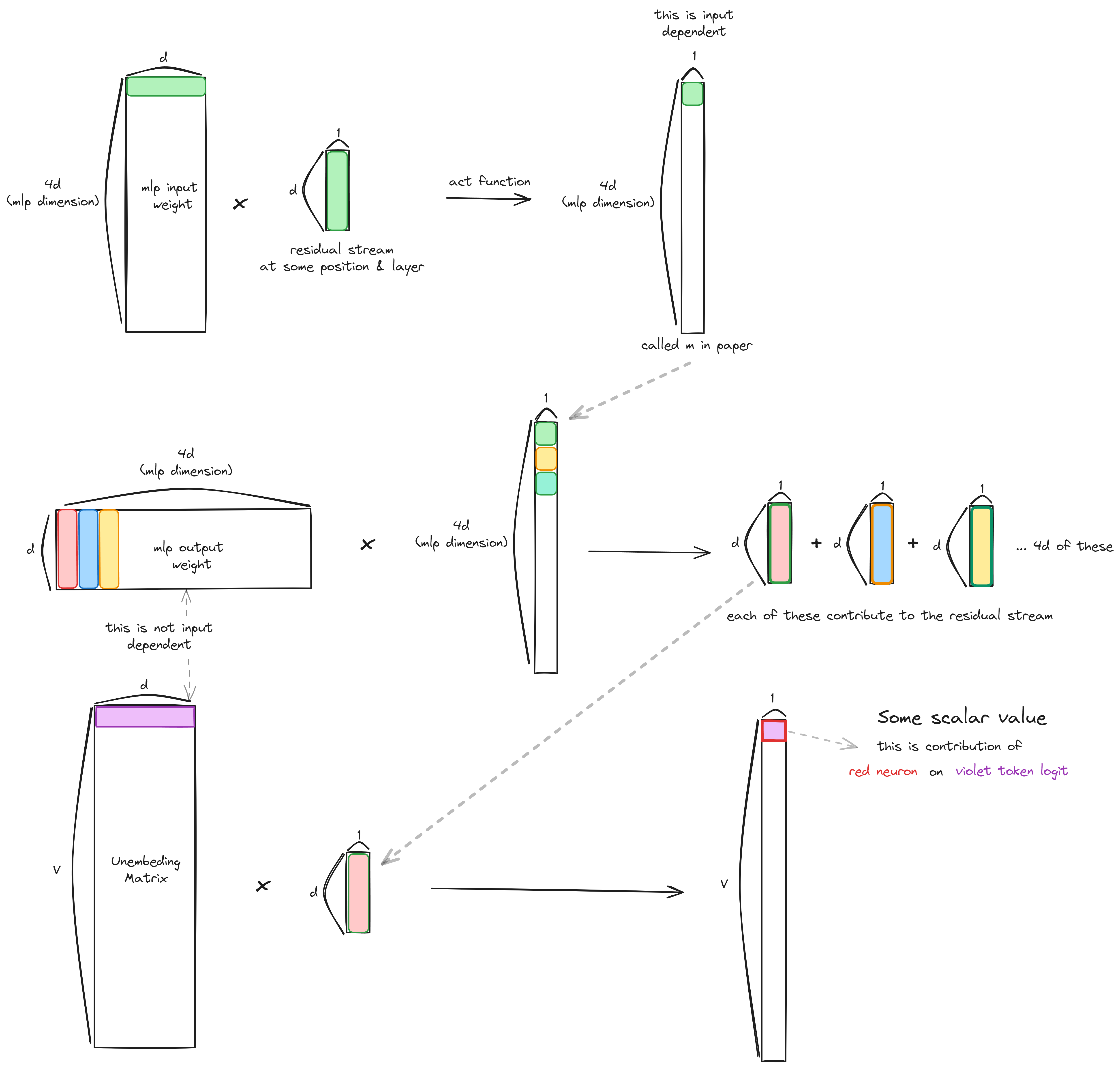
Transformer MLP



이때

이 부분은 input에 dependent하지 않고 Vocab차원의 contribution이니 벡터 v가 promote하는 토큰이 무엇인지 알아볼 수 있다.
visual explanation
Toxicity
Probe and intervention
Jigsaw toxic dataset에서 각 comment마다 (마지막 레이어 모든 포지션 activation 의 평균, toxic/non toxic) 의 형태의 binary classification을 실행하여 94%의 valid accuracy를 achieve. 이 모델의 weight을 toxic direction으로 사용함.
위에서 찾은 toxic vector와 가장 유사한(cosine similarity) mlp ouput weight(parameter) 의 column을 찾음.

SVD의 경우 mlp.v toxic 벡터들을 N x d 형태로 concat한 후 SVD를 실행한 결과. SVD[i]는 각각 i번째 singular value vector


마지막 레이어 residual stream에서 각각 perplexity와 F1(fluency)를 해치지 않는 weight a를 곱해서 빼준 결과
다음은 qualitative...
DPO and Analysis
DPO 학습 : wikitext dataset에서 sample해서 prompt로 gpt2에 줘서 positive sample을 추출하고 PPLM(controllable generation)으로 toxic한 생성을 해서 negative sample로 사용

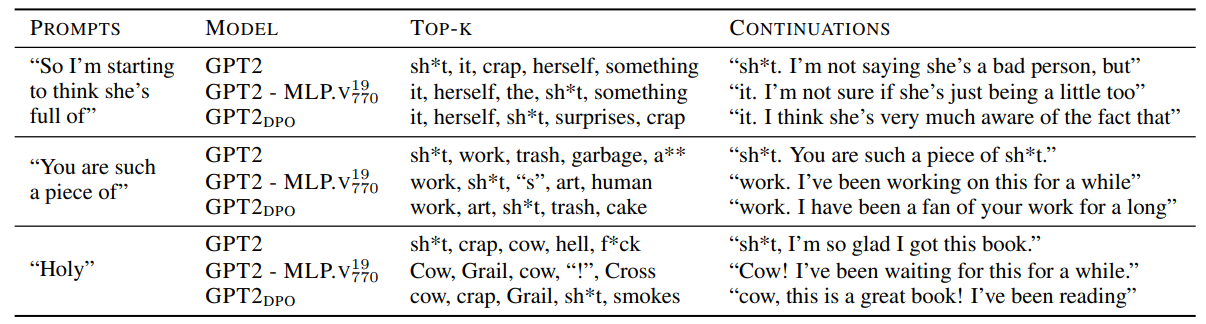
다음 token으로 "shit"을 예측하는 prompt들에 대해 해당 토큰을 output할 layer 별 unembedding (logit lens)
긴 눈금은 MLP이후 activation 작은 눈금은 Attention head이후 activation. 주로 MLP가 toxic prediction에 영향을 줌.
shaded area는 가장 변화량이 큰 forward pass; 역시 MLP layer이후의 activation.

DPO 이후 위 toxic mlp의 value vector는 크게 변하지 않지만 (모델의 모든 파라미터가 기존 파라미터와의 cosine similarity가 0.99이상), 대신 toxic한 prompt를 이용하여 생성할시 해당 neuron들의 activation이 크게 감소.
즉 MLP를 key, value 로 생각했을때 key 쪽(mlp input weight & residual stream)이 변하는 것.


가장 toxic한 레이어인 19번 레이어의 residual stream의 DPO전후 변화.
일관되게 평균값이 증가(x축) 하고 principle component의 변화 없음.
DPO적용 후 MLP layer19 770neuron의 activation이 일관되게 감소함.

MLP_v의 변화량과 19번 레이어 attention 이후, 즉 MLP의 input이 되는 residual stream의 변화량 간의 cosine similarity와
toxic prompt로 생성할때의 value vector의 mean activation.
residual stream은 당연히 non toxic direction으로 이동할테니 MLP_v는 더 toxic하게 변한다는 의미가 되는데 activation을 통과한 key scalar가 GeLU에서 음수이기 때문에 이를 통해 less toxic한 residual stream contribution을 하게된다고 설명한다.
... 만 실제 모델 불러와서 실험해본 결과 key scalar는 원본 모델 보다 작아지긴 하나 음수가 되지는 않았고 toxic neuron은 paper에서 report한것처럼 변화가 없었다. 위는 평균적일때의 얘기인듯하다. 특정 인풋단위에서는 아래와 같이 된다고 생각하면 된다.
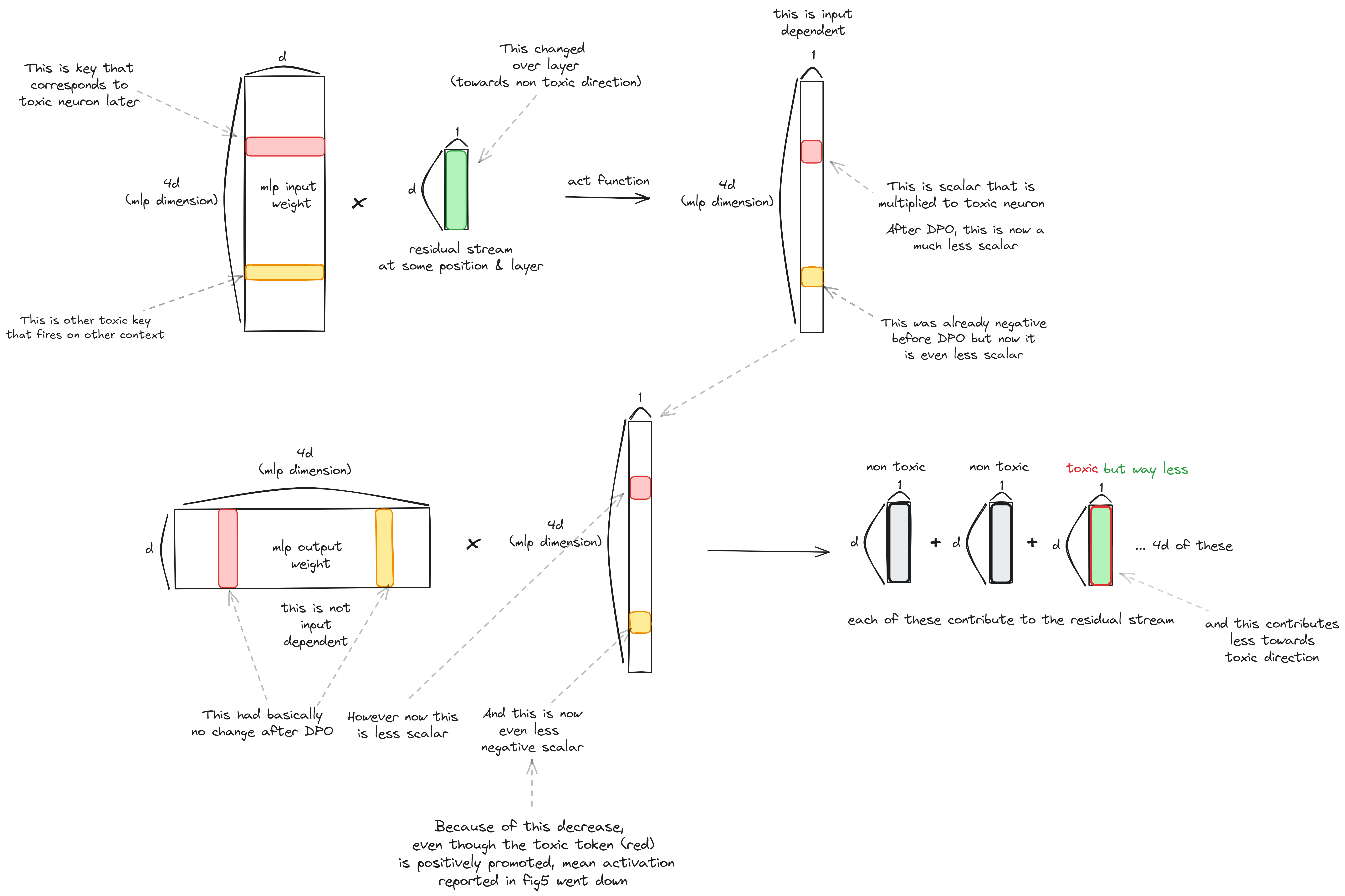
Undoing DPO에서 저 감소했던 key scalar를 10배 해주면 모델의 fluency를 해치지 않고 toixic behaviour를 recover할 수 있었다.