https://arxiv.org/pdf/2311.04897
모델의 hidden state(residual stream)가 당장 다음 토큰 외 그 이후의 토큰도 예측하는가?
Related works
logit lens, tuned lens 등 residual stream에서 각 레이어에서 next token prediction을 만들어가는 과정을 human interpretable하게 볼 수 있음
이와 연관되게 모델의 prediction 도중의 layer에서 바로 early decoding 하는 연구도 있음
여기서는 그에 대한 follow-up으로 당장 다음토큰뿐 아니라 그 뒤의 토큰까지 예측할 수 있음을 보임
Methods
preliminaries
논문에서는 GPT (decoder only transformer)를 다룬다.

E : embedding
D : unembedding (decoding)
b : 각 레이어
x : input
으로 나타낼 수 있고


H : residual stream
h : residual stream의 각 position (input sequence 상)에 해당하는 d_model의 벡터
T : 모델 inference시 주어진 prompt (혹은 그 길이)

y : logit
주어진 prompt이후로는 다음과 같이 생성 (greedy sampling)
vocabulary prediction

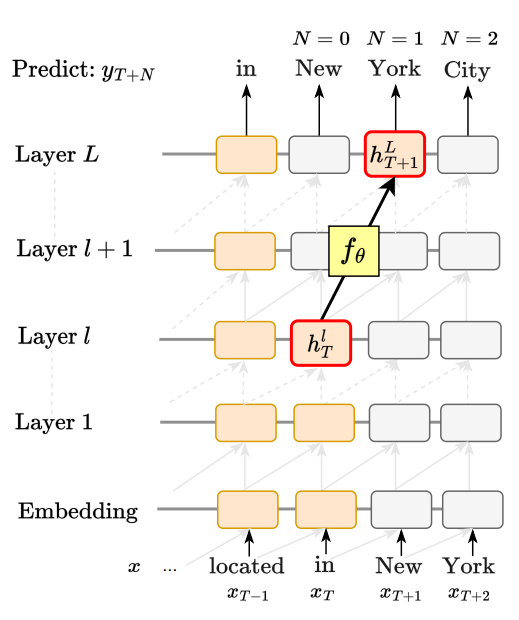
residual stream 마지막 포지션(T번째, early layer l)를 linear layer(g theta)에 통과시켜서 T+N포지션의 logit 분포를 예측하게함
hidden state prediction

residual stream 마지막 포지션(T번째, early layer l)를 linear layer(f theta)에 통과시켜서 T+N포지션의 마지막 레이어의 residual stream output을 예측하게함
causal intervention (activation patching)

original prompt x (X_T+1 부터 New York City) 와 general prompt c ( “Please, tell me something about" )를 두고 original prompt에서 mid layer residual stream h_T를 general prompt inference time에 해당 레이어 " about" 포지션에 삽입. 이후 general prompt에서 " New" 토큰 뿐 아니라 그 이후 " York", " City"까지 출력된다면 h_T에는 T번 토큰 뿐 아니라 그 이후 토큰에 대해서도 encode되어있다 할 수 있다.
causal intervention (activation patching & prefix tuning)

위 activation patching과 유사하지만 general prompt 대신 실제로 이 future token을 더 잘 예측해주는 prompt(soft)를 학습시킨다(prefix tuning). general prompt 제외, 모델 전체를 freeze하고 위처럼 activation patching 했을때와 original prompt에서 T+N포지션 최종 softmax 이후 logit분포의 kl divergence를 loss로 하여 soft prompt를 학습시킨다.
(그림에서는 hidden state의 kl divergence이지만 논문에서의 수식과 코드상 최종 logit분포의 kl divergence이다)
Experiments
setup
model : GPT_J
dataset : the Pile에서 base 모델이 평균적으로 535 token의 context가 주어진 상태에서 autoregressive 하게 prediction을 맞춘(greedy sampling) datapoint를 사용
evaluation :
precision@k : T+N번 포지션 토큰 예측에서 top-k 개 토큰에 정답이 포함 되었는가? ↑
surprisal : information content. 정답 토큰에 대한 negative log probability. ↓
implementations
linear models
위 vocab prediction과 hidden state prediction모두 linear layer로 구현
각 레이어마다 최종토큰 T기준 +0번째, +1번째, +2번째, +3번째 의 토큰/residual을 예측하는 linear모델을 각각 만든다.
이때 +0번째 토큰 예측은 사실상 tuned lens와 동일.
fixed prompt activation patching

위 고정 prompt를 general prompt로 사용하고 마지막 토큰에서의 residual stream을 patching한다.
prefix tuning activation patching
마찬가지 방법에서 앞의 general prompt를 미래토큰 정답예측을 잘 할 수 있도록 학습한다. prompt길이는 empirically 10 token 길이로한다
Results

각 레이어 +N번 포지션 예측에 대한 precision@1의 plot
N=1일때 learned prompt방식에서 bigram baseline보다 약 2배의 성능을 보여준다.

surprisal 역시 mid layer residual에 learned prompt 방식이 가장 성능이 좋다.
N=0 (logit lens)의 경우와는 다르게 future token에 대해서는 후반 레이어가 아닌 중반 레이어에서 가장 잘 표현되는것을 확인 할 수 있다.
이후 추가적인 실험내용 (plot/table 제공없음)
1. model confidence 와 future token prediction accuracy가 비례함.
confidence를 0~30, 30~60, 60~90, 90~100 구간으로 나누었을때 각각 N=1 에서의 accuracy가 각각 26% 57% 77% 95%
2. future token에 대한 information은 high level / human interpretable하지 않을 수 있음.
멀티토큰 named entity에 대해서 future token prediction 결과 N=1,2,3 전부 전체적인 accuracy보다 비슷하거나 더 낮게 나옴
Discussion

단순히 다음토큰 예측에 대해 볼 수 있는 logit lens / tuned lens를 넘어서 그 뒤의, 실질적으로 모델이 뭘 "생각"하고 있는지를 확인할 수 있는 tool이 된다. (future lens)
"from"에서 그 이후를 예측할때 early layer에서는 from이라는 토큰 자체에 연결해서 Austria 등 국가/지역을 낮은 confidence로 예측하다가 어느 mid layer에서 movie, 그 이후 정답에 해당하는 Back to the Future를 예측하는 것을 확인할 수 있다.
해볼만한 실험들
1. ICL스타일 sythetic data에서 더 clear한지?
2. model agnostic 한지?
3. 미래 토큰에 대한 정보를 ablate했을때 language modeling에 어떤 영향을 주는지?